

Transcript condensed and edited from the original audio. Thanks to both Tim Pease and Grant Rodgers of Github for taking the time to answer these questions!
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account

 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Transcript condensed and edited from the original audio. Thanks to both Tim Pease and Grant Rodgers of Github for taking the time to answer these questions! 
No comment yet.
Sign up to comment
“So, how much experience do you have with Big Data and Hadoop?” they asked me. I told them that I use Hadoop all the time, but rarely for jobs larger than a few TB. I’m basically a big data neophite - I know the concepts, I’ve written code, but never at scale. The next question they asked me. “Could you use Hadoop to do a simple group by and sum?” Of course I could, and I just told them I needed to see an example of the file format. They handed me a flash drive with all 600MB of their data on it (not a sample, everything). For reasons I can’t understand, they were unhappy when my solution involved pandas.read_csv rather than Hadoop. [...]
Nico's insight:
"But my data is more than 5TB! - Your life now sucks - you are stuck with Hadoop". Quite true.

A month back, one of our clients asked us to set up 15 individual single-node Cassandra instances, each of which would live in 64MB of RAM and each of which would reside on the same machine. My first response was “Why!?” [...]
Nico's insight:
Sometimes you don't need to scale up but to scale down. Nice recipe.
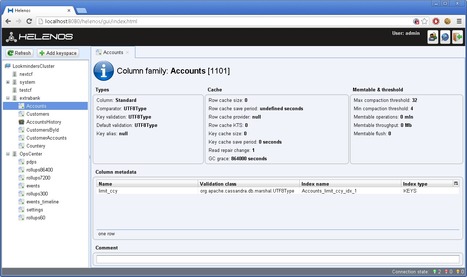
Helenos is a web based GUI tool to manage your data stored in Apache Cassandra
Nico's insight:
A sexier frontend to Cassandra than its command line
From
ferd

Your ( ) tweet ( ) blog post ( ) marketing material ( ) online comment advocates a way to beat the CAP theorem. Your idea will not work. Here is why it won't work: ( ) you are assuming that software/network/hardware failures will not happen ( ) you pushed the actual problem to another layer of the system ( ) your solution is equivalent to an existing one that doesn't beat CAP ( ) you're actually building an AP system ( ) you're actually building a CP system ( ) you are not, in fact, designing a distributed system [...]
Nico's insight:
Funny list of wrong assumptions in a distributed system

Ordasity is a library designed to make building and deploying reliable clustered services on the JVM as straightforward as possible. It's written in Scala and uses Zookeeper for coordination. Ordasity's simplicity and flexibility allows us to quickly write, deploy, and (most importantly) operate distributed systems on the JVM without duplicating distributed "glue" code or revisiting complex reasoning about distribution strategies.
Nico's insight:
Its API seems pretty straight forward. It needs a Zookeeper cluster though.
If like many humans you've found even Paxos Made Simple a bit difficult to understand, you might enjoy RAFT as described in In Search of an Understandable Consensus Algorithm by Stanford's Diego Ongaro and John Ousterhout. The video presentation of the paper is given by John Ousterhout. Both the paper and the video are delightfully accessible.
Nico's insight:
Not everyone has to implement consensus algorithm, but as users Raft is probably a nice win over Paxos considering the current implementations; if you pardon my french, Zookeeper tends to be described as a PITA.
At AddThis, we deployed our first production system written in Scala almost two years ago. Since then, a growing stack of new applications are built using this exciting language. Among the many native Scala libraries we have tried and adopted, Akka stands out as the most indispensable
Nico's insight:
The more I read about Akka, the more I like it.

Being clever about system architecture in advance is hard. Scaling successfully is more about being clever with metrics and introspection, creating efficient build and provisioning processes and being comfortable with radical change.
Nico's insight:
Non technical article on how to plan your scalling. I think at Scoop.it we are on the same track: keep it simple and pragmatic.
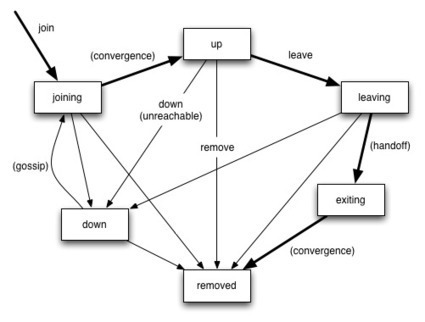
Akka Cluster provides a fault-tolerant, elastic, decentralized peer-to-peer cluster with no single point of failure (SPOF) or single point of bottleneck (SPOB). It implements a Dynamo-style system using gossip protocols, automatic failure detection, automatic partitioning [*], handoff [*], and cluster rebalancing [*]. But with some differences due to the fact that it is not just managing passive data, but actors - active, sometimes stateful, components that also have requirements on message ordering, the number of active instances in the cluster, etc. [*] Not Implemented Yet
Nico's insight:
This looks awesome. And very promising since the "not implemented yet".
Hive Deep Dive, Hive 0.11 Tuning tips, Hive 0.11 performance optimizations, and Tez
Nico's insight:
I've only skim read the slides, but there are nice hints about Hive internals related to performance. To bookmark and use when shit happens.

Samza is a stream processing system for running continuous computation on infinite streams of data. Proposal Samza provides a system for processing stream data from publish-subscribe systems such as Apache Kafka. The developer writes a stream processing task, and executes it as a Samza job. Samza then routes messages between stream processing tasks and the publish-subscribe systems that the messages are addressed to.
Nico's insight:
Probably yet another hadoop component which will require a deployment of many processes
When discussing the tradeoffs between availability and consistency, we say that a distributed system exhibits strong consistency when a reader will always see the most recently written value. It is easy to see how we can achieve strong consistency in a master-based system, where reads and writes are routed to a single master. However, this also has the unfortunate implication that the system must be unavailable when the master fails until a new master can take over. Fortunately, you can also achieve strong consistency in a fully distributed, masterless system like Cassandra with quorum reads and writes. Cassandra also takes the next logical step and allows the client to specify per operation if he needs that redundancy — often, eventual consistency is completely adequate. But what if strong consistency is not enough? What if we have some operations to perform in sequence that must not be interrupted by others, i.e., we must perform them one at a time, or make sure that any that we do run concurrently will get the same results as if they really were processed. This is linearizable consistency, or in ACID terms, a serial isolation level.
Nico's insight:
Very light, but they are transactions, because they do a little more than atomic operations.
|
Specialists are in demand but when it comes to scaling the web companies will need generalists to the lead the way. Recently at Surge 2011, the annual conference on scalability and performance, Google’s CIO Ben Fried gave an illuminating keynote address. His main insight was that generalists are the people that will lead engineering teams in successfully scaling the web. In a world where the badge of Specialist or Expert is prized, this was refreshing perspective from an industry bigwig. As tech professionals, or any professional for that matter, we don’t welcome the label of generalist. The word suggests a jack-of-all-trades and master of none. But the generalist is no less an expert than the specialist. Generalists can get their hands greasy with the tools to fix bugs in the machine but they are especially good at mobilizing the machine itself; with their talents of broad vision, and perspective they can direct an entire team to accomplish tasks efficiently. This ability to see big-picture can not be underestimated especially during times of crisis or pressure to meet targets. For a team to scale the web effectively, you’re going to need a good mix of both types of personalities.
Nico's insight:
I always had issues with the "expert" thing. Hands get dirty in too many technologies to be an expert in anything.
The headlining features in 2.0 are lightweight transactions, CQL enhancements, and triggers. But 2.0 also features a lot of internal optimizations and improvements!
Nico's insight:
An nice list of performance improvements. I'd still wait few versions to deploy it into production (just my guts talking, not a real hint).
Rick Branson - @rbranson Aphyr - @aphyr Rick Branson - @rbranson [...] Kelly Sommers - @kellabyte Aphyr - @aphyr
Nico's insight:
Aphyr's work on testing very carefull distributed database is awesome. And this spawn very deep discussion on twitter, with a lot of smart people.

Nico's insight:
"The Spark codebase is small, extensible, and hackable." "hackable" ? I should love it then ! I tried so many time to dig into Hive, and so many times I actually broke it and made it behave incoherently. I'm done trying to improve it. Too much frustration.
Let’s face it—designing distributed systems can be tough. There’s just no one-size-fits-all tool for creating distributed services: Every distributed application has a unique set of tolerances with regard to reliability, scalability, response time, and other performance factors. At Gilt, our toolbox for supporting distributed service development includes Apache ZooKeeper, RabbitMQ, Kafka and a smattering of distributed data stores. We made these technology choices based on years of hands-on development at Gilt, decades of cumulative experience across our engineering team and (literally) endless internal debate.
Nico's insight:
They show an interesting use of Ordasity

The Eventsourced library adds scalable actor state persistence and at-least-once message delivery guarantees to Akka. With Eventsourced, stateful actors persist received messages by appending them to a log (journal)
Nico's insight:
Interesting kind of persistence for Akka actors

Riak Pipe is most simply described as “UNIX pipes for Riak.” In much the same way you would pipe the output of one program to another on the command line, Riak Pipe allows you to pipe the output of a function on one vnode to the input of a function on another. This talk covers the basic structure of Riak Pipe, with an emphasis on the structures and practices used to prevent overload. An analysis of the strengths and weaknesses of the approaches chosen, and potentials for future improvement, will also be presented.
Nico's insight:
Seems awesome, but there is the Erlang language barrier.
Anti-entropy repair in Cassandra can sometimes be a pain point for those doing deletes in their cluster, since it must be run before gc_grace expires to ensure deleted data is not resurrected.Reliable hints can go a long way to alleviating this, but if you lose a node at any point, you’ll still need to repair (though it’s worth mentioning that if you only delete via TTL, and only inserted with a TTL to begin with, you can skip repair if your cluster has synchronized time, which it should for a variety of reasons.)
Nico's insight:
"Repair" is a known pain in Cassandra. Riak has a more automated one : Active Anti-Entropy

HBase offers both scalability and the economy of sharing the same infrastructure as Hadoop, but will its flaws hold it back? NoSQL experts square off. HBase is modeled after Google BigTable and is part of the world's most popular big data processing platform, Apache Hadoop. But will this pedigree guarantee HBase a dominant role in the competitive and fast-growing NoSQL database market? Michael Hausenblas of MapR argues that Hadoop's popularity and HBase's scalability and consistency ensure success. The growing HBase community will surpass other open-source movements and will overcome a few technical wrinkles that have yet to be worked out. Jonathan Ellis of DataStax, the support provider behind open-source Cassandra, argues that HBase flaws are too numerous and intrinsic to Hadoop's HDFS architecture to overcome. These flaws will forever limit HBase's applicability to high-velocity workloads, he says. Read what our two NoSQL experts have to say, and then weigh in with your opinion in the comments section below.
Nico's insight:
One funny pro-HBase argument is that there's worst: MongoDB. :D I don't like Jonathan Ellis status though: "where he sets the technical direction and leads Apache Cassandra as project chair.". I hope that's not true. At the ASF the project chair is supposed to be an administrative task, the lead is done by a PMC (Project Management Community), aka the devs, by consensus. He may have influence, but it's social, not by title or rule.

“ I’d like to welcome Britta Weber (“brwe“) to our team (long overdue…). Britta is almost done with her PhD in computer science, developing Machine Learning algorithms to process electron microscopy image data. ”
Nico's insight:
Elasticsearch is going to rock at data mining. See a piece of her work: https://github.com/elasticsearch/elasticsearch/issues/3307

The Spanner paper by Google (appeared in OSDI'12) is cryptic and hard to understand. When I first read it, I thought I understood the main idea, and that the benefit of TrueTime was to enable lock-free read-only transactions in Spanner. Then, I slowly realized things didn't check; it was possible to achieve lock-free read-only transactions without TrueTime as well. I did another read, and thought for some time, and had a better understanding of how TrueTime benefits Spanner, and how to improve its shortcomings.
Nico's insight:
Spanner. I still don't understand it all, but we should keep reading about it, it will probably bring ideas on other distributed databases.

Twilio experienced an incident with its billing system on July 18, 2013. Although we’ve shared how the incident unfolded, and the impact on our customers, we’d like to detail the root cause, how we fixed it, and what we’re doing to ensure this doesn’t happen in the future.
Nico's insight:
Interesting story about what happens when the network connectivity breaks down between the nodes of a distributed database, here Redis.
|





Very nice story, with drama, suspens and happy ending