

 Your new post is loading...
Your new post is loading...
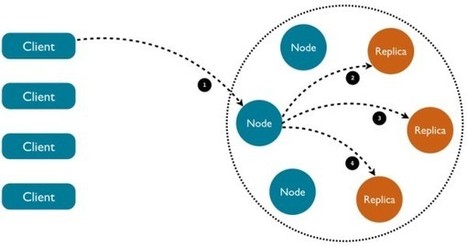

Proper error handling with databases is always a challenge when the safety of your data is involved. Cassandra is no exception to this rule. Thanks to the complete control of consistency, availability and durability offered by Cassandra, error handling turns out to be very flexible and, if done right, will allow you to extend the continuous availability of your cluster even further. But in order to reach this goal, it’s important to understand the various kind of errors that can be thrown by the drivers and how to handle them properly.
To remain practical, this article will refer directly to the DataStax Java Driver exceptions and API, but all the concepts explained here can be transposed directly to other DataStax Drivers.




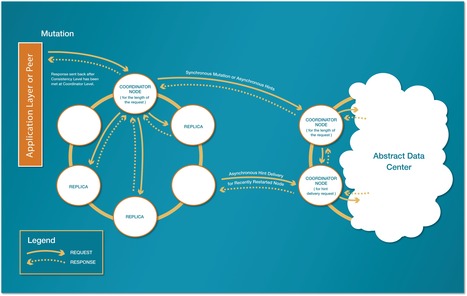






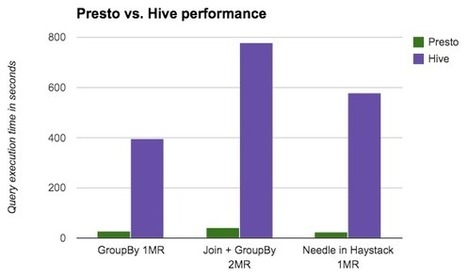


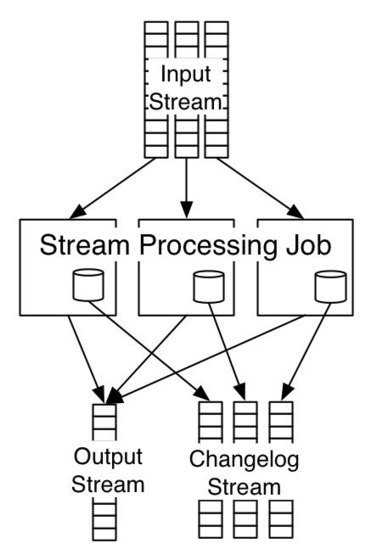
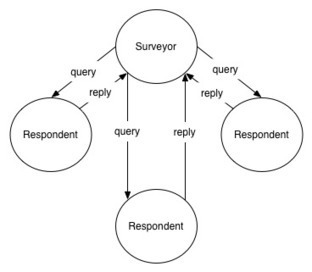

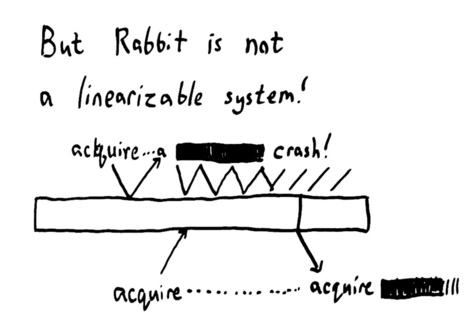





One of the main behaviour to understand in a distributed database is how it will fail