



Hadoop and Apache Spark are both big-data frameworks, but they don't really serve the same purposes.
Get Started for FREE
Sign up with Facebook Sign up with X
I don't have a Facebook or a X account


 Your new post is loading...
Your new post is loading... Your new post is loading...
Your new post is loading...
Hadoop and Apache Spark are both big-data frameworks, but they don't really serve the same purposes. 

Carsfinance's comment,
November 27, 2023 12:20 AM
good

magicmushroomsdispensary's comment,
March 20, 2:52 AM
nice

Sip and Paint DC's comment,
April 3, 3:32 AM
good
Sign up to comment

The Internet of Things continues to grow more popular, and the network of devices connected to it gets bigger every day. Gartner has estimated that there will be 26 billion devices connected to the IoT within the next six years.
Luca Naso's insight:
Up to now the Internet of Things has mainly focused on the data generation part (sensors and devices).
It is now time for the Analytics side to take over. Here is where Hadoop can make the difference.
However, my expectations are that IoT will boom with Real-Time analytics, and Hadoop can be of little use in this scenario.

A new, free eBook, Introducing Microsoft Azure HDInsight, covers Microsoft's implementation of Big Data through Hadoop compliance.
Luca Naso's insight:
120 pages for professional programmers on how Microsoft is using Hadoop to dive into Big Data: 1. Intro to Big Data 2. Intro to HDInsight 3. Programmgin with HDInsight 4. HDInsight and Data 5. Customisation

So there's not a huge percentage of enterprises in production yet but now the momentum is building, and a huge production wave is coming for Hadoop.
Luca Naso's insight:
At the moment, companies are nowhere near reaching their individual data frontiers. They only use 12% of the data they already have, because data are siloed and they have a portfolio of hundreds of applications!
Data science is very different from traditional analytics. Traditional analytics are based on managers' theories and is a human-driven approach. On the data science side, it's very different. We don't need a big meeting. We don't need your hypotheses. We don't need your ideas. What we need is all the data you've got.

Windows Azure HDInsight Service lets customers to spin up Hadoop clusters in the cloud
Luca Naso's insight:
Good news for all Microsoft's Softwares users: Standard Apache Hadoop is available as a service in Microsoft's Azure cloud, allowing to deploy and shut down Hadoop clusters easily. Integration with the Microsoft data platform means that one can access and analyze data with PowerPivot, Power View and other Microsoft BI tools, like Microsoft SQL Server Analysis Services (SSAS).

Apache Hadoop Big Data Analytics Tool and Technology: Defination, Advantages, Disadvantages
Luca Naso's insight:
Pro and cons of one of Apache Hadoop, one of the most famous and used platform for working with Bigh Data.
Pro: 1. Cheap 2. Fast 3. Scales to large amounts of big data storage 4. Scales to large amounts of big data computation 5. Flexible with types of big data 6. Flexible with programming languages
1. Hard to to set up 2. Hard to manage 3. Hard to keep alive 4. Hard to use 5. Is not secure 6. Is not optimized for your hardware

Big data was the buzzword of the day today during our second day of IBM training on analytics and, for my social media marketers, today had a BIG
Luca Naso's insight:
Think about all those Tweets and Facebook Status Updates about your brand. Think about all those consumers talking about unmet needs, dissatisfaction with their current products, and new features they’d love to see in the products they own. How much do you hear of what your customers are saying about your products? Start developing a plan on how to collect, store and analyse those data. And then give them to your marketing experts. They will be very grateful to you ;)
|

With Big Data solutions spawning the requirement for applications focusing on Data Analytics, HANA’s capabilities are serving as the perfect partner for Hadoop. Read this article to know more about this perfect combination
Luca Naso's insight:
SAP HANA and Hadoop are very different, that's why they could be a good combination in terms of complementing each other. For example, SAP HANA is in-memory and uses predefined schema, while Hadoop is on disk and has no schema.
A scalable column-oriented database management for real-time analytics (SAP HANA) meets a technology platform that supports any kind of data for analyzing massive amount of data (Hadoop).
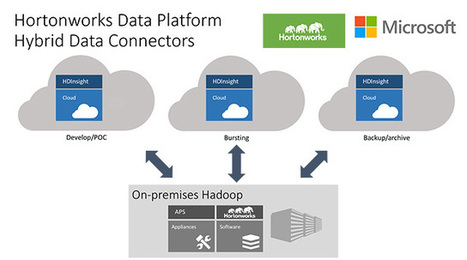
There has been a spate of product announcements and integrations over the past few weeks signaling that many big data workloads — including, and especially, Hadoop — will soon be ready to run reliably in the cloud.
Luca Naso's insight:
I cannot think of any other place for Big Data but the cloud! Amazon and Microsoft are clear leaders at the moment, but there is a lot of movements and Oracle might well catch up. My Hadoop clusters have always been running on the cloud and will always be (I am currently using HDInsight on Azure).

Hadoop is a savior of this big data world. This article gives an introduction to this tool.
Luca Naso's insight:
This is an extremely basic description of Hadoop, and yet it introduces relevant concepts: parallelism and MapReduce.

The Hadoop Innovation Summit features two days of engaging content from the most hands-on engineers & architects working with Hadoop. Check back regularly on the evolving and growing schedule here.
Luca Naso's insight:
By 2015, 65 percent of applications with advanced analytics will come embedded with Hadoop. There's never been a better time to unlock the power of your Big Data.
This post from Chris Stuccio's blog takes a critical look at the use of Hadoop and Big Data as buzzwords by asking an interesting question: What if your data isn't as big as you think?
Luca Naso's insight:
Hadoop works well with Big Data, but really Big data. Before diving yourself into Hadoop check whether you really need it or maybe your data isn't that Big.
Here you can find solutions for datasets of a variety of sizes: 1. Hundreds of megabytes 2. Ten-ish gigabytes 3. A couple of terabytes 4. Five terabytes and larger

Data Scientist Daniel D. Guiterrez's highlights from the 6th Hadoop Summit.
Luca Naso's insight:
If there was any doubt that the Apache Hadoop platform has captured the hearts and minds of big data believers everywhere, the recent Hadoop Summit in San Jose on June 26 and 27, 2013, may have settled the question once and for all.
|





In my opinion, Spark should NOT be compared with Hadoop but with MapReduce. However, people usually compare Hadoop and Spark (probably because they are buzzwords).
5 things to keep in mind:
1. They do different things -
Hadoop is a distributed data infrastructure (HDFS),
Spark is a data-processing tool.
2. Hadoop is more complete -
Hadoop also includes a data-processing tool (MapReduce),
Spark does not have its own filesystem and needs to be integrated with some.
3. Spark is (much) faster -
MapReduce operates in step;
Spark operates in one shot (because it is in-memory).
4. Speed is not always what you need -
For batch processing you do not need Spark's high velocity;
Common applications for Spark are those requiring real-time analysis.
5. Failure recovery -
both Hadoop and Spark are resilient to failures.